保持一致性: Journaling
29 Aug 2012 by fleuria
一个比较容易混淆的概念是,Journaling主要负责的是数据一致性的维护,而并不特别关心数据的恢复。
上篇post记了些FFS相关的笔记,不过忽略了文件系统的Journaling,在这里单独记一下。
情景
凡是需要分多次写才能完成的一项任务,如果在中途中断便有可能会造成不一致。
文件系统中的操作恰恰大多为分步进行,除了对数据块的操作,更附带着对元数据的更新。试想删除一个文件的情景1,顺序如下:
- 删除目录中对应的目录项
- 释放inode
如果1与2之间系统崩溃,那么就会形成一个不被任何目录项引用的inode,然而它的引用计数大于零,无法回收利用。换句话说,这就造成了文件系统元数据的不一致。
同步写
上一篇post中提到,文件系统会尽量等缓存中的数据块成簇,再一齐写入,考虑到磁盘的机械原理,这样可以大大地增大文件系统的吞吐。
然而代价是,写操作的顺序无法保证。回到上面删除文件的情景,如果写操作的顺序反了过来:
- 释放inode
- 删除目录中对应的目录项
如果在两步操作之间系统崩溃,目录中就留有了一项错误的映射,引用了一个不存在的inode。到这里还不是大问题,fsck可以轻松解决它。
真正糟糕的是,如果这个inode号被一个新的文件使用了,那么目录中的这项映射就奇怪地指向了一个不相干的文件,fsck将无法辨认哪个目录项才是正确的。
可见保证两项写的顺序是有必要的。然而性能呢?每写一次数据,随着更新一次元数据,机械臂免不了来来回回运动一番。磁盘大块读大块写的愿景也就破坏了。
崩溃恢复
在系统启动时,会首先执行一次fsck进行一致性检查。
如果存在不一致问题,则遍历文件系统中的冗余信息尽力修复。若出现类似上文提到的fsck无法确认的问题,就出现一个交互界面,让用户来给出选择。
用过Windows XP的我们一定对强制关机后的蓝色界面中消耗掉的时间之长印象深刻。可以想见,fsck是一件相当耗时的工作。
A Simple Solution To Above All
便是Journaling。
将文件系统的所有变更追加到一个日志文件中。系统崩溃之后,只要检查日志文件的末尾,即可在一定程度上恢复崩溃时进行的操作,快速地恢复文件系统的一致性。2
Journaling的写入很容易做到连续的大块写,符合磁盘的机械性质。此外因为有了Journaling做保证,原先文件系统中的同步写可以得到消除,在某种程度上对性能也是更加有益的。
What To Log
记录文件系统中所有数据的变更是个有吸引力的方案,然而会大幅地损失性能。试图兼顾写性能与所有数据可靠的Log-structured FS则属于全新的文件系统结构,并非为既有的文件系统加入journaling支持的可行方向。
退一步,可以只记录元数据3的变更,止于保证文件系统本身的一致性。至于用户数据的一致性可以交给用户程序自己来保证——毕竟不是所有的应用程序都对数据的一致性敏感。
Metadata Logging
可见Metadata Logging是一条很中庸的解决方案:
- 不需要修改文件系统的结构,保持了原先文件系统的兼容;
- 性能与一致性之间的平衡;
- 易于实现。
Redo-only Log以及约束
日志文件系统中的技术与术语许多都是来自数据库的事务处理。不过一些不同允许文件系统的Journaling实现简化许多:
- 文件系统中的事务不会中断
- 文件系统中事务的寿命相对较短
从而文件系统无需考虑事务的回滚,也无需考虑事务之间复杂的依赖关系。只要在日志中将变更记录下来,必要时根据日志“重播”这些变更就够了。这种仅用于“重播”的日志,被称作Redo-only Log。
简化归简化,几项约束仍必须遵守:
-
Ordering Garantee:
保证实写必须在Log写入磁盘之后;
-
Transactional Garantee:
如果是连续的两项操作,那么必须先保证两项操作的Log都已写入磁盘,随后才能实写(实写的顺序则不重要)。
约束的意义就在于,只要满足了少数的几条原则,其余的任何优化都可以做。
实例:BFS
BFS采用Metadata Logging为既有的文件系统提供了Journaling支持,并给出了一个简单的实现(不到1000行,可惜没有开源)。
BFS将以下操作视为事务:
- 创建/删除一个文件或者目录
- 重命名一个文件
- 更改文件的大小
- 创建/更改/删除文件的atrribute
BFS为journal预留了一块固定大小的区域,以循环缓冲区(Circular Buffer)的形式使用。
每条journal的内存布局与磁盘布局如下:
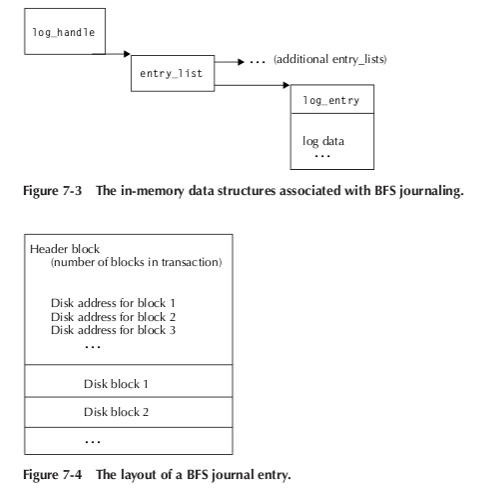
可见每条journal中的数据以块为单位,第一块用以记录数据块的数目以及数据块到盘块地址的映射,后跟修改过的数据块。
它的接口十分简单,只有3个函数:
-
struct log_handle* start_transaction(bfs_info *bfs);负责新建一个事务,并且:
- 获取日志的互斥访问
- 执行一些检查工作,比如日志的可用空间是否足够
-
ssize_t log_write_blocks(bfs_info *bfs, struct log_handle *lh, off_t block_number, const void *data, int number_of_blocks);记录一项新的变更。
这里有一条优化是,如果在事务期间同一数据块被多次修改,只保留最后的版本即可。
-
int end_transaction(bfs_info *bfs, struct log_handle *lh);结束一个事务,这时会:
- 必要时,将日志在内存中的Cache写入磁盘
-
同时为日志在内存中的每块Cache绑定一个回调函数。
这个回调函数会在这块Cache被写入完成后被调用,用以获知何时整个事务写入完毕。
Batching Transactions(或者Group Commit)
出于性能的考虑,BFS并不会在调用end_transaction()时立即将journal写入磁盘,而是将多个事务攒起来,一齐写入。这里只要保证实写在事务写入完毕之后的约束就好了。
实例:Ext2
与BFS为一条操作新建事务然后Group Commit的策略不同,ext2只保留一个全局的事务,一段时间内系统的所有元数据的写操作都交给这同一个事务来记录,随后一齐写入。
Collisions Between Transactions
出于性能考虑,在写入事务期间并不会阻止创建新的事务。如果新的事务需要修改提交中的事务中的数据会怎么办?
这里的一个Workaround是,拷贝一份这块数据的Cache到一块临时的Buffer中,将新的修改都放在这块Buffer上。待前一个事务提交完毕,将这个Buffer中的内容拷贝回数据块对应的Cache即可。
References
- Unix Internals
- the Design and Implementation of 4.4BSD
- Practical File System Design
- Journaling the Linux ext2fs Filesystem
- The Design and Implementation of a Log-Structured File System
Footnotes
- 简单起见,这里假定文件的引用计数为1。
- 但不一定能保证数据不丢失,也不一定能保证用户数据的一致性。这就是为什么数据库程序仍需要自己实现一套Journaling机制的原因之一。
- 甚至可以只记录影响一致性的部分,至于时间戳等不那么重要的字段也可以忽略。